Diversity
How diverse is your LinkedIn network?My phone rings, it's Ryan. "Muriel, can you program in LinkedIn?", he asks. Well, I know how to program and I use LinkedIn, so I say "Sure Ryan, what do you need?". Ryan wants to show people how diverse their networks are compared to the cities they live in. The idea is to increase awareness and make people aware of their unconscious biases. When translated into Machine Learning Lingo, the goal of this project is to predict Ethnicity and Gender using first and last name data of a person's LinkedIn network.
Results
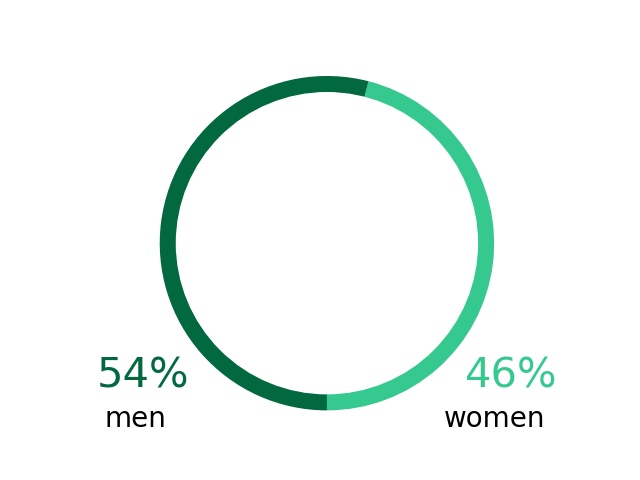
I've managed to build it into a simple and easy to use application which predicts the diversity of your network from a .csv file which you can easily download from LinkedIn. Below is an example of what my network looks like. The graphs are easy to understand and interpret and compare to the population of the city you live in.
Gender in your network:
Ethnicity in your network:
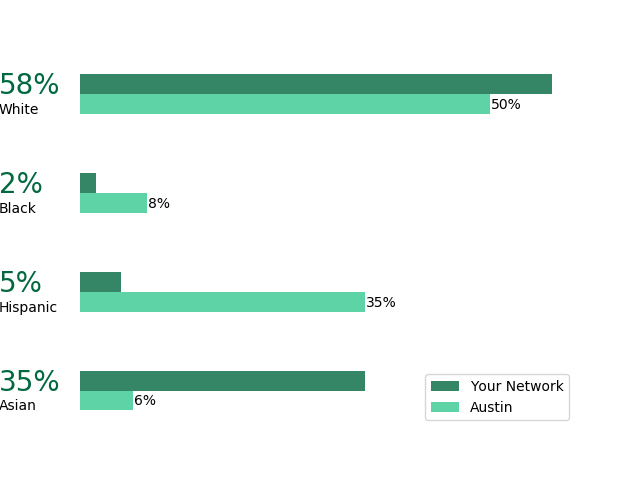
Approach
A labeled dataset containing 3200 entries was used to train and test the model. Gender predictions were done this dataset from Dataworld determine the gender of contacts based on first names only. The model simply predicts gender based on the frequency at which names have been given to boys or girls between 1930 and 2015.
Ethnicity is predicted using three data sources: Wikipedia (origin of names), US Census data and a NY labeled set of baby names. For the Wikipedea data, a NLP model was created by S. Laohaprapanon and G. Sood and can be found here . Secondly,ethnicity is assigned to first and last names based on the frequency of occurence. These three datasets were used to train a Random Forest Model .
Outcome
The gender prediction based on first names is surprisingly accurate (96% on individual level). Depending on the specific make-up of your network, the aggregated results will vary from this. For the testing data, a 99.7% accuarcy was obtained. The reason for this number being higher is because misclassification happens in both directions: Jaime and Pat are both names which can be given to either boys or girls. The model will predict Jaime as male and Pat as female. Depending on the amount of Jaime's and Pat's in your network two mis-labeled genders could cancel out in aggregated results.
Ethnicity predictions were about 82% accurate based on individual data. Depending on the make-up of the network, the model will perform better or worse. Originally, the main misclassification occured between nh_black and white. This is logical considering the African American population has been living in the US for longer than Hispanic and Asian communities and so names are no longer a strong indication of ethnicity between these two groups. This was corrected for by increasing the weight of the "nh_black" categorical variable (at the cost of other ethnicities). Results from the testing data for the final model is shown below. The model was deemed accurate enough to move to production.
| Ethnicity | Actual | Predicted |
|---|---|---|
| Asian | 4.8 % | 2.6 % |
| Hispanic | 5.8 % | 7.7 % |
| Non-Hispanic White | 84.4 % | 85.4 % |
| Non-Hispanic Black | 5.0 % | 4.4 % |